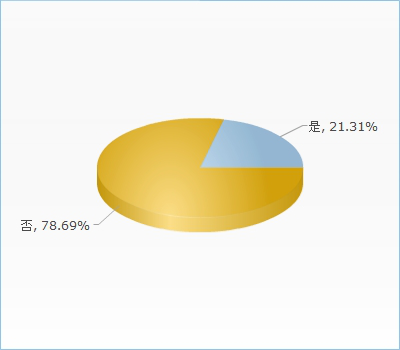
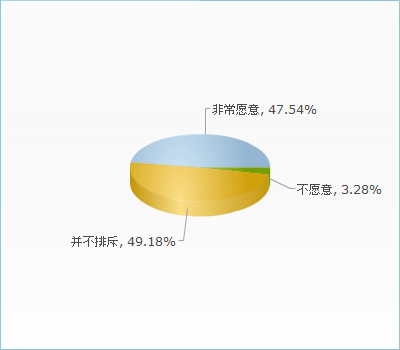
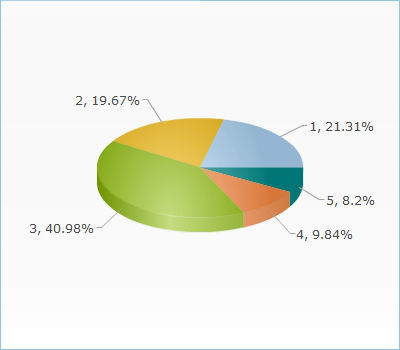
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
本周六我们进行了一整个下午的详尽讨论,围绕以下几点进行了细致的分析,并且有了比较明晰的结论。
APP的名字
这是最早被提出的问题,但也可能是(不只是一个笨手笨脚的大作业,对于所有的项目都是)最难的一个问题之一。这几乎不涉及技术问题,而是需要外对于整体产品和用户市场、内对于项目定位的一个精准的把控。
由于条件的限制,我们并不能在这一点上花费太多的时间,我们认为基于我们实际情况的最佳的名字应该能够同时反映信息收集 + (基于共同关注点的)社交这两点,在头脑风暴中,我们想了很多正儿八经以及奇奇怪怪的名字。
- 信息人大
- 校园风
- 三人行
- 校园通
- 圈里信息
- 校园知事
最终我们比较中意的是“校园知事”,它满足了我们提出的两点基本要求,并且发音同“芝士”也让人多少有些亲切感(→_→ Fate第十职阶Eater)。暂定这个名字,只有有更好的想法再进行修改。
关于《需求规格说明书》以及《可行性分析报告》
在定下了基本的思路与设计之后我们开始着手书面材料。第一步要做的就是《需求规格说明书》以及《可行性分析报告》。在《需求规格说明书》中我们将按照课件上的标准进行编写,并且对成员进行了分工,具体分工如下:
- 第一部分:系统规格说明:小男孩。内容包括系统概貌、功能要求、性能要求、运行要求、可能增加的要求、DFD、IPO
- 第二部分:数据要求:纪神。内容包括DD、Hierarchy或Warnier Diaggram
- 第三部分:用户系统描述:爵爷。内容包括初步用户手册:从用户的观点考虑系统,系统功能、性能 、使用与步骤
- 第四部分:修正的开发计划:老板。 内容包括成本估计 ,资源使用计划 ,进度计划等。
在《可行性分析报告》上,如果按照业界正式工程的格式来做的话会非常繁冗,并且其中涉及的市场背景、政策背景、法律背景以及资金链等对于我们目前来说有些不切实际,所以我们对于《可行性分析报告的规格》的格式进行了适应性调整。主要分为六个部分:
- 背景了解以及基于问卷调查的需求分析
- 对市场现有的产品进行分析对比
- 我们满足这个需求的思路想法
- 技术层面上实现我们的思路想法
- 产品的测试和维护
- 产品的推广和运营
《可行性分析报告》将于《需求规格说明书》之后完成,届时将根据情况进行调整。预计最晚于下周末完成《需求规格说明书》和《可行性分析报告》这两份书面材料。
关于微人大权限以及各院API接口
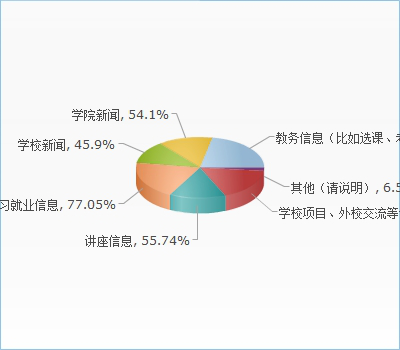
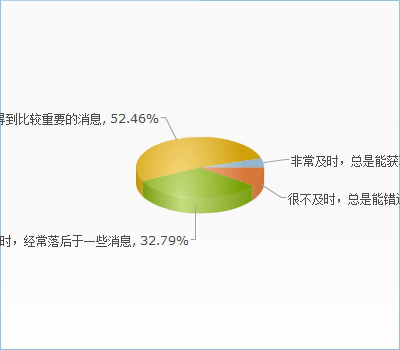
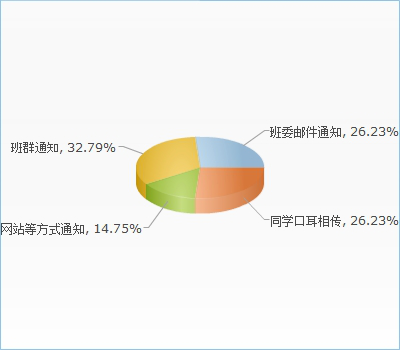
因为涉及人大身份(目前APP只覆盖人大范围)验证问题,我们需要微人大的开发者权限,并且在信息收集这方面如果能直接拿到各个学院的新闻API岂不美哉[王司徒脸]。
在微人大权限上,我们在微人大上申请了开发者账号,系统说7日之内会给回复,然而两个七日过去了······再等等,再催催好了,另外关于微人大的讨论中又催生出了一个问题:登录模式。是直接采用微人大账号登录还是新注册账号登录,再于APP中进行人大身份验证(就像进入APP后再进行邮箱验证一样)。经过讨论我们认为,如果使用微人大账号登录虽然直接方便,但是给人一种官方死板的气息(不吹不黑),且不利于之后用户群体的扩展(怎么能占领清华北大呢);使用独立账号注册 + 后期验证的方式虽然多了一步流程,但是让人感觉不受束缚(这种感觉很难描述),并且可以让用户先体验一部分功能,并有利于之后对清华北大的占领工作。
在各院新闻API获取这方面,我们以尽可能诚恳的语气向30多个学院发送了邮件,分析了共赢新性并询问是否能拿到新闻的接口,但截至目前没有任何学院给予回复(其实也难怪,人大黄页上找到的邮箱地址有好几个格式都是错的,还有几个要么没这个主机要么没这个用户)。我们并不准备就以上的经历来分析办事效率问题,因为很可能是我们的方法出了问题。目前看来用爬虫抓新闻是比较可行的选择,现阶段无法预料在爬虫部分将遇到的问题,我们将于下周写一份爬虫的demo,并连接LeanCloud进行测试。
做最小化原型的详细功能设计以及简略的UI
这两部分是结合在一起做的,在简要功能的讨论中画出了主要的UI。我们不在这里贴出讨论过程中的草图,之后我们会用原型设计软件重新把图画一遍再发布。主要的界面就是新闻消息、 好友、发现(与自己关注点相同的人,了解自己最近的关注点或者查看自己的时间轴等等)以及更多(个人信息以及应用设置等)。虽然这是至关重要的一点,但是我们认为于”空想阶段“在这上面花费太多的时间不太合适,应该结合最小化原型设计出一个简略的功能框架,然后在做的过程中踩坑。
进度安排
在这点上我们同样无法做出细致的估计,因为涉及公关处理、策略转型或团队配合等方方面面的问题,我们只是做了一个大阶段的预期。
- 四月份: 第一版开发与测试
- 五月份: 第一版集中测试,第二版开发与测试
- 六月份: 第二版集中测试,产品推广
总体来说我们目前的进度是可以接受的,在第一版的开发过程中一定会遇到非常多的问题,而且这些问题中有些将超出我们的预期与能力(即所谓的”坑“),我们会翔实地把这个过程中的心得体会记录下来,作为之后的一个宝贵的参考。