Docker Multi-Stage Builds
Docker 的 multi-stage 技术可以把不同的构建阶段分离开,方便修改和复用,同时还能更好地把缓存层组合在一起,避免重复劳动,还能保证最后运行时的干净纯粹,不会带入前边阶段的副产品。不过我在实际场景中遇到的问题比单纯的构建更加复杂一些——我不仅需要不同的构建阶段(build stage),还需要在不同的环境里构建同一个镜像,比如在本地和在 CI/CD 中。CI/CD 的特殊之处在于在前边的阶段中基本上已经完成了 dependency download, build, package 等一系列阶段,因此直接把 build 的结果拷贝到 Docker context 里执行 Dockerfile 的最后几步就可以了。如果复用一个 Dockerfile,那么基本上要做前边的很多重复工作,如果用两份 Dockerfile,则又会造成配置上的冗余,迟早会出幺蛾子。
为了解决这个问题,我打算使用 Docker 的 multi-stage 来做,本意是把 package 之后的几步合并到一个 stage 里,在前边的 build 阶段来区分不同的环境。就像下边的配置一样,设想中这个流程非常完美,Docker 可以根据 ENVIRONMENT 来区分不同的环境,并且在最后的 runtime 阶段中从不同的环境构建阶段中把二进制内容拷贝出来。
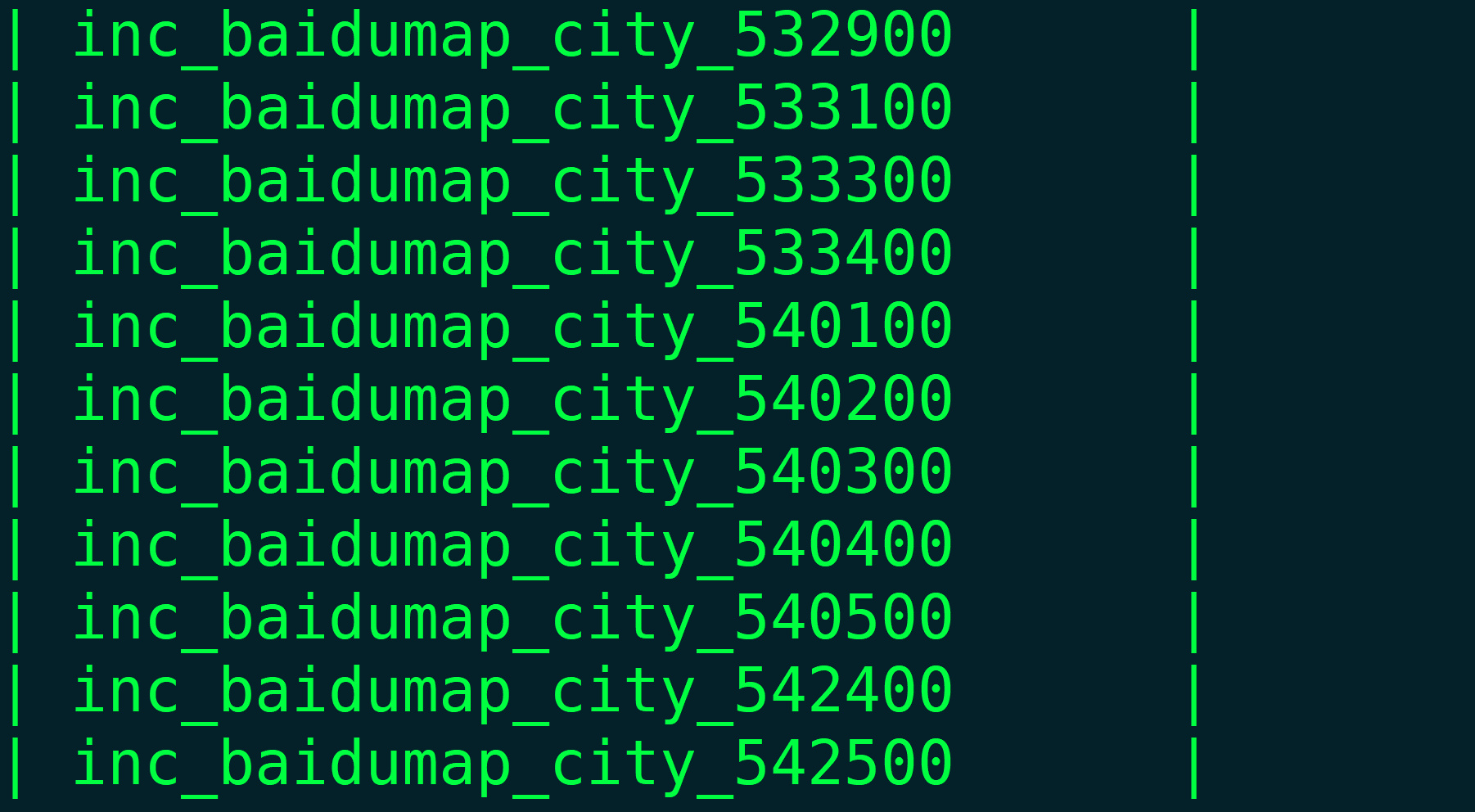
1 | FROM ubuntu:22.04 AS build-base |
但是这样做有个非常大的问题就是 Docker 的 build arguments 是只在单个阶段之内管用的,因此倒数第二行的 COPY 压根不认识 ENVIRONMENT 这个变量,进而这个 Dockerfile 根本无法正常构建。找了很多解决方案,最终看到虽然在 Docker 某一个阶段内不认识其他阶段的 build arguments,但是在定义阶段本身的时候是可以复用的,也就是 FROM runtime-base AS runtime 这一行,在这里是可以用 ENVIRONMENT 这个变量的。因此思路就很清晰了,可以直接改成下边这种情形:
1 | FROM ubuntu:22.04 AS build-base |
但这样有个最大的问题,就是最后的 runtime 阶段直接继承前边 build 阶段,会把这些阶段运行过程中的副产品、垃圾文件和系统包带到最后,这显然极大地违背了 multi-stage 的初衷。继承还是要继承的,关键是不能从 build 阶段继承,那么自然而然地就想到再加上一层干净的 ready 阶段来过渡,保证 ready 阶段中的内容是纯粹的二进制,每个环境都有自己对应的 ready 阶段,然后分别把自己的二进制拷贝进去就行,如下配置:
1 | FROM ubuntu:22.04 AS build-base |
这样就可以完美地解决上边的所有问题,除了多出两个几乎一样的 build stages 以外没有什么成本。只要在执行 docker build 的时候传进入对应的 ENVIRONMENT 参数就行。还要注意的是,一定要使用 Docker Buildkit 来执行,这样才会根据最后的 runtime 阶段有挑选地执行需要的阶段,否则 Docker 会傻乎乎地执行所有的阶段,这样就得不偿失了。